Model penalaran Kecerdasan Buatan (AI) tidak secerdas mereka. Bahkan, mereka sebenarnya tidak benar -benar beralasan, para peneliti di Apple Say.
Model penalaran, seperti Meta's Claude, Openai's O3 dan Deepseek's R1, adalah model bahasa besar khusus (LLM) yang mendedikasikan lebih banyak waktu dan daya komputasi untuk menghasilkan tanggapan yang lebih akurat dari pendahulu tradisional mereka.
Munculnya model -model ini telah menyebabkan klaim baru dari perusahaan teknologi besar bahwa mereka bisa berada di ambang mesin pengembangan Kecerdasan Umum Buatan (AGI) – Sistem yang mengungguli manusia di sebagian besar tugas.
Namun sebuah studi baru, diterbitkan 7 Juni pada Situs Web Research Pembelajaran Mesin Appletelah merespons dengan mendapatkan pukulan besar terhadap pesaing perusahaan. Model penalaran tidak hanya gagal menunjukkan penalaran umum, kata para ilmuwan dalam penelitian ini, akurasinya benar -benar runtuh ketika tugas menjadi terlalu kompleks.
“Melalui eksperimen yang luas di berbagai teka -teki, kami menunjukkan bahwa LRM Frontier menghadapi keruntuhan akurasi yang lengkap di luar kompleksitas tertentu,” tulis para peneliti dalam penelitian ini. “Selain itu, mereka menunjukkan batas penskalaan yang berlawanan dengan intuisi: upaya penalaran mereka meningkat dengan kompleksitas masalah hingga titik tertentu, kemudian menurun meskipun memiliki anggaran token yang memadai.”
LLMS tumbuh dan belajar dengan menyerap data pelatihan dari sejumlah besar output manusia. Menggambar pada data ini memungkinkan model untuk menghasilkan pola probabilistik dari jaringan saraf mereka dengan memberi makan mereka ke depan saat diberi prompt.
Terkait: Ai 'berhalusinat' terus -menerus, tetapi ada solusi
Model penalaran adalah upaya untuk lebih meningkatkan akurasi AI menggunakan proses yang dikenal sebagai “rantai-pemikiran.” Ini bekerja dengan melacak pola melalui data ini menggunakan respons multi-langkah, meniru bagaimana manusia dapat menggunakan logika untuk sampai pada kesimpulan.
Ini memberi chatbots kemampuan untuk evaluasi kembali alasan merekamemungkinkan mereka untuk menangani tugas yang lebih kompleks dengan akurasi yang lebih besar. Selama proses rantai yang dipikirkan, model mengeja logika mereka dalam bahasa sederhana untuk setiap langkah yang mereka ambil sehingga tindakan mereka dapat dengan mudah diamati.
Namun, karena proses ini berakar pada dugaan statistik alih -alih pemahaman nyata, chatbots memiliki kecenderungan yang nyata untuk 'berhalusinasi' – membuang keluar tanggapan yang salah, berbohong Ketika data mereka tidak memiliki jawaban, dan mengeluarkan aneh dan sesekali berbahaya Saran untuk pengguna.
Sebuah Laporan Teknis Openai telah menyoroti bahwa model penalaran jauh lebih mungkin untuk digelincirkan oleh halusinasi daripada rekan -rekan generik mereka, dengan masalah hanya semakin buruk seiring berjalannya model.
Ketika ditugaskan untuk meringkas fakta tentang orang-orang, model O3 dan O4-mini perusahaan menghasilkan informasi yang salah 33% dan 48% dari waktu, masing-masing, dibandingkan dengan tingkat halusinasi 16% dari model O1 sebelumnya. Perwakilan Openai mengatakan mereka tidak tahu mengapa ini terjadi, menyimpulkan bahwa “diperlukan lebih banyak penelitian untuk memahami penyebab hasil ini.”
“Kami percaya kurangnya analisis sistematis yang menyelidiki pertanyaan -pertanyaan ini adalah karena keterbatasan dalam paradigma evaluasi saat ini,” tulis para penulis dalam studi baru Apple. “Evaluasi yang ada sebagian besar fokus pada tolok ukur matematika dan pengkodean yang sudah ada, yang, meskipun berharga, sering menderita masalah kontaminasi data dan tidak memungkinkan untuk kondisi eksperimental yang terkontrol di berbagai pengaturan dan kompleksitas. Selain itu, evaluasi ini tidak memberikan wawasan tentang struktur dan kualitas jejak penalaran.”
Mengintip di dalam kotak hitam
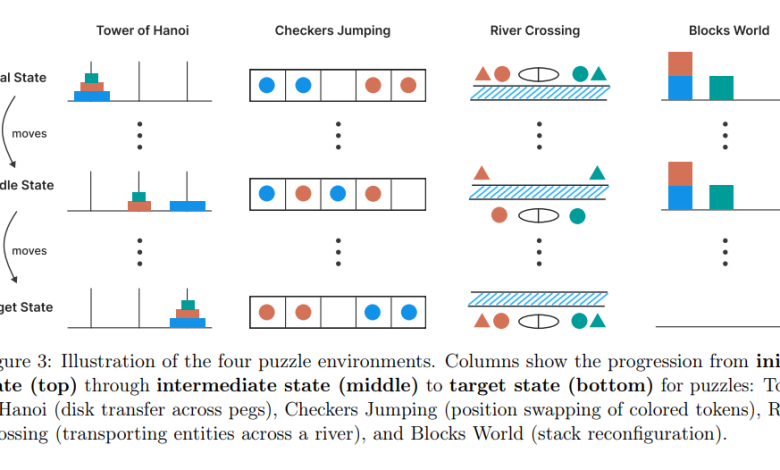
Untuk menggali lebih dalam tentang masalah ini, penulis studi baru menetapkan bot generik dan penalaran-yang meliputi model O1 dan O3 Openai, Deepseek R1, Anthropic's Claude 3.7 Sonnet, Google Gemini-empat teka-teki klasik untuk dipecahkan (persimpangan sungai, lompatan checker, penandakan blok, dan block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, River Crossing, River Crossing, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stacking, block-stack Menara Hanoi). Mereka kemudian dapat menyesuaikan kompleksitas teka -teki antara rendah, sedang dan tinggi dengan menambahkan lebih banyak potongan pada mereka.
Untuk tugas-tugas rendah kompleksitas, para peneliti menemukan bahwa model generik memiliki keunggulan pada rekan-rekan penalaran mereka, memecahkan masalah tanpa biaya komputasi tambahan yang diperkenalkan oleh rantai penalaran. Ketika tugas menjadi lebih kompleks, model penalaran mendapatkan keuntungan, tetapi ini tidak bertahan ketika dihadapkan dengan teka -teki yang sangat kompleks, karena kinerja kedua model “runtuh menjadi nol.”
Setelah melewati ambang batas kritis, model penalaran mengurangi token (model blok bangunan mendasar memecah data menjadi) yang mereka tetapkan untuk tugas yang lebih kompleks, menunjukkan bahwa mereka lebih sedikit penalaran dan memiliki keterbatasan mendasar dalam mempertahankan rantai yang dipikirkan. Dan model terus mencapai hambatan ini bahkan ketika diberikan solusi.
“Ketika kami memberikan algoritma solusi untuk Tower of Hanoi kepada model, kinerja mereka pada teka -teki ini tidak membaik,” tulis para penulis dalam penelitian ini. “Selain itu, menyelidiki gerakan kegagalan pertama dari model mengungkapkan perilaku mengejutkan. Misalnya, mereka dapat melakukan hingga 100 gerakan yang benar di menara Hanoi tetapi gagal memberikan lebih dari 5 gerakan yang benar di teka -teki persimpangan sungai.”
Temuan ini menunjukkan model yang lebih mengandalkan pengenalan pola, dan lebih sedikit pada logika yang muncul, daripada mereka yang menandakan klaim intelijen mesin yang akan segera terjadi. Tetapi para peneliti memang menyoroti keterbatasan utama untuk studi mereka, termasuk bahwa masalah hanya mewakili “irisan sempit” dari tugas penalaran potensial yang dapat ditugaskan oleh model.
Apple juga memiliki kuda tertinggal dalam perlombaan AI. Perusahaan itu membuntuti para pesaingnya dengan siri ditemukan oleh satu analisis 25% kurang akurat dari chatgpt dalam menjawab pertanyaan, dan malah memprioritaskan pengembangan AI on-device, efisien daripada model penalaran besar.
Ini pasti membuat beberapa orang menuduh Apple anggur asam. “Strategi AI baru Apple yang brilian adalah untuk membuktikannya tidak ada,” Minggu Pedrosseorang profesor emeritus ilmu komputer dan teknik di University of Washington, menulis dengan bercanda tentang x.
Meskipun demikian, beberapa peneliti AI telah menandakan penelitian sebagai penumpukan air dingin yang diperlukan klaim muluk Tentang kemampuan AI Tools saat ini untuk suatu hari nanti menjadi pengawas.
“Apple did more for AI than anyone else: they proved through peer-reviewed publications that LLMs are just neural networks and, as such, have all the limitations of other neural networks trained in a supervised way, which I and a few other voices tried to convey, but the noise from a bunch of AGI-feelers and their sycophants was too loud,” Andriy Burkovseorang ahli AI dan mantan pemimpin tim pembelajaran mesin di firma penasihat penelitian Gartner, menulis di x. “Sekarang, saya berharap, para ilmuwan akan kembali melakukan sains nyata dengan mempelajari LLMS sebagai matematikawan studi berfungsi dan bukan dengan berbicara dengan mereka ketika psikiater berbicara dengan orang sakit.”