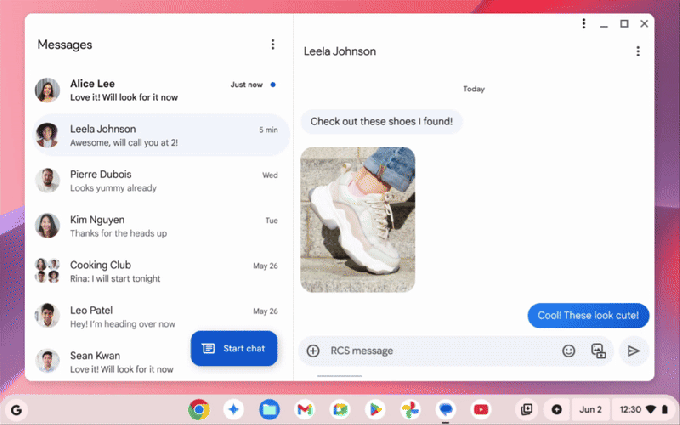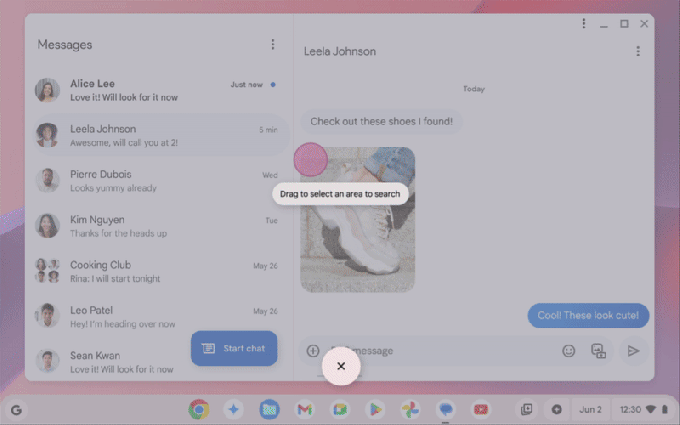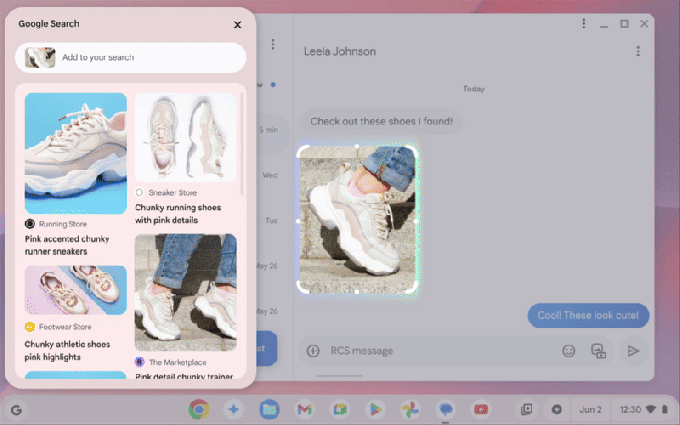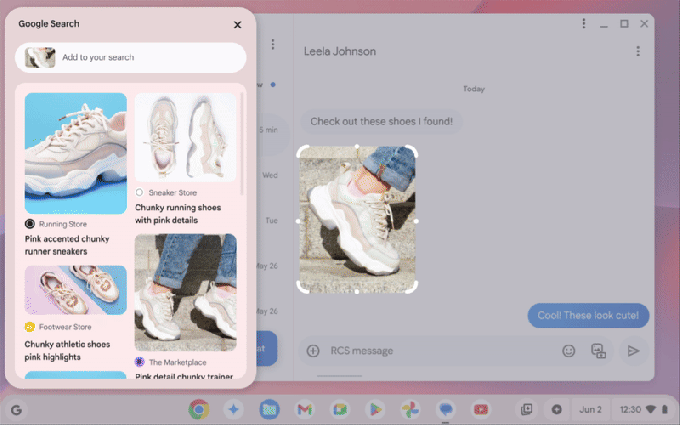
Seorang siswa sekolah menengah membangun situs web yang memungkinkan Anda menantang model AI untuk membangun minecraft
Sebagai konvensional Benchmarking AI Teknik terbukti tidak memadai, pembangun AI beralih ke cara yang lebih kreatif untuk menilai kemampuan model AI generatif. Untuk satu kelompok pengembang, itu adalah Minecraft, game pembangun Sandbox milik Microsoft.
Situs web Benchmark Minecraft (atau MC-Bench) dikembangkan secara kolaboratif untuk mengadu model AI satu sama lain dalam tantangan head-to-head untuk menanggapi petunjuk dengan kreasi Minecraft. Pengguna dapat memilih model mana yang melakukan pekerjaan yang lebih baik, dan hanya setelah pemungutan suara mereka dapat melihat AI mana yang membuat setiap minecraft membangun.

Bagi Adi Singh, siswa kelas 12 yang memulai MC-Bench, nilai Minecraft bukanlah permainan itu sendiri, tetapi keakraban yang dimiliki orang-orang dengan itu-bagaimanapun juga, itu adalah terlaris video game sepanjang masa. Bahkan untuk orang -orang yang belum memainkan permainan, masih mungkin untuk mengevaluasi representasi bloki mana dari nanas yang lebih terwujud.
“Minecraft memungkinkan orang untuk melihat kemajuan [of AI development] Jauh lebih mudah, “kata Singh kepada TechCrunch.” Orang -orang terbiasa dengan minecraft, terbiasa dengan tampilan dan getaran. “
MC-Bench saat ini mencantumkan delapan orang sebagai kontributor sukarela. Antropik, Google, OpenAi, dan Alibaba telah mensubsidi penggunaan produk mereka untuk menjalankan petunjuk tolok ukur, per situs web Mc-Bench, tetapi perusahaan tidak berafiliasi.
“Saat ini kami hanya melakukan bangunan sederhana untuk merefleksikan seberapa jauh kami telah datang dari era GPT-3, tetapi [we] Bisa melihat diri kita menskalakan rencana yang lebih panjang ini dan tugas-tugas yang berorientasi pada tujuan ini, “kata Singh.” Permainan mungkin hanya media untuk menguji alasan agen yang lebih aman daripada dalam kehidupan nyata dan lebih terkendali untuk tujuan pengujian, membuatnya lebih ideal di mata saya. “
Game lain seperti Pokémon Red, Street FighterDan Pictionary telah digunakan sebagai tolok ukur eksperimental untuk AI, sebagian karena seni benchmarking AI terkenal rumit.
Peneliti sering menguji model AI Evaluasi standartetapi banyak dari tes ini memberi AI keuntungan bidang rumah. Karena cara mereka dilatih, model secara alami berbakat pada jenis-jenis pemecahan masalah tertentu, khususnya pemecahan masalah yang membutuhkan hafalan hafalan atau ekstrapolasi dasar.
Sederhananya, sulit untuk mendapatkan apa artinya GPT-4 Openai dapat mencetak gol dalam persentil ke-88 di LSAT, tetapi tidak dapat membedakan Berapa banyak Rs dalam kata “stroberi.” Antropik Claude 3.7 Sonnet mencapai akurasi 62,3% pada tolok ukur rekayasa perangkat lunak standar, tetapi lebih buruk dalam bermain Pokémon daripada kebanyakan anak berusia lima tahun.

MC-Bench secara teknis adalah tolok ukur pemrograman, karena model diminta untuk menulis kode untuk membuat build yang diminta, seperti “Frosty the Snowman” atau “Pondok pantai tropis yang menawan di pantai berpasir murni.”
Tetapi lebih mudah bagi sebagian besar pengguna MC-Bench untuk mengevaluasi apakah manusia salju terlihat lebih baik daripada menggali kode, yang memberikan daya tarik proyek yang lebih luas-dan dengan demikian potensi untuk mengumpulkan lebih banyak data tentang model mana yang secara konsisten mendapat skor lebih baik.
Apakah skor tersebut sangat berarti dalam cara kegunaan AI siap diperdebatkan, tentu saja. Singh menegaskan bahwa mereka adalah sinyal yang kuat.
“Papan peringkat saat ini sangat mencerminkan pengalaman saya sendiri dalam menggunakan model -model ini, yang tidak seperti banyak tolok ukur teks murni,” kata Singh. “Mungkin [MC-Bench] Bisa bermanfaat bagi perusahaan untuk mengetahui apakah mereka menuju ke arah yang benar. “