Openai membawa transkripsi baru dan model AI yang menghasilkan suara ke API-nya yang diklaim perusahaan meningkat pada rilis sebelumnya.
Untuk Openai, model -model tersebut cocok dengan visi “agen” yang lebih luas: membangun sistem otomatis yang dapat secara mandiri menyelesaikan tugas atas nama pengguna. Definisi “agen” mungkin dalam perselisihantetapi kepala openai dari produk Olivier Godement menggambarkan satu interpretasi sebagai chatbot yang dapat berbicara dengan pelanggan bisnis.
“Kita akan melihat semakin banyak agen muncul dalam beberapa bulan mendatang,” kata Godement kepada TechCrunch saat pengarahan. “Dan tema umum membantu pelanggan dan pengembang memanfaatkan agen yang berguna, tersedia, dan akurat.”
Openai mengklaim bahwa model teks-ke-ucapannya yang baru, “GPT-4O-Mini-TTS,” tidak hanya memberikan pidato yang lebih bernuansa dan terdengar realistis tetapi juga lebih “diatur” daripada model sintesis pidato generasi sebelumnya. Pengembang dapat menginstruksikan GPT-4O-Mini-TTS tentang bagaimana mengatakan hal-hal dalam bahasa alami-misalnya, “berbicara seperti ilmuwan gila” atau “menggunakan suara yang tenang, seperti guru perhatian.”
Inilah “gaya kejahatan sejati,” suara lapuk:
Dan inilah contoh suara “profesional” wanita:
Jeff Harris, anggota staf produk di Openai, mengatakan kepada TechCrunch bahwa tujuannya adalah untuk membiarkan pengembang menyesuaikan suara “pengalaman” dan “konteks”.
“Dalam konteks yang berbeda, Anda tidak hanya menginginkan suara yang datar dan monoton,” kata Harris. “Jika Anda dalam pengalaman dukungan pelanggan dan Anda ingin suara itu meminta maaf karena itu membuat kesalahan, Anda sebenarnya dapat memiliki suara memiliki emosi di dalamnya … Keyakinan besar kami, di sini, adalah bahwa pengembang dan pengguna ingin benar -benar mengendalikan bukan hanya apa yang diucapkan, tetapi bagaimana hal -hal diucapkan.”
Adapun model-model ucapan-ke-teks baru Openai, “GPT-4-Transcribe” dan “GPT-4O-Mini-Transcribe,” mereka secara efektif menggantikan perusahaan yang panjang di gigi perusahaan Model Transkripsi Whisper. Dilatih tentang “beragam, kumpulan data audio berkualitas tinggi,” model-model baru ini dapat lebih baik menangkap ucapan beraksen dan beragam, klaim openai, bahkan di lingkungan yang kacau.
Mereka juga cenderung berhalusinasi, Harris menambahkan. Berbisik cenderung membuat kata -kata – dan bahkan seluruh bagian – dalam percakapan, memperkenalkan segala sesuatu mulai dari komentar rasial hingga perawatan medis yang dibayangkan ke dalam transkrip.
“[T]Modelnya jauh lebih baik versus bisikan di bagian depan itu, “kata Harris.” Pastikan modelnya akurat sangat penting untuk mendapatkan pengalaman suara yang andal, dan akurat [in this context] berarti bahwa model mendengar kata -katanya secara tepat [and] tidak mengisi detail yang tidak mereka dengar. “
Namun, jarak tempuh Anda dapat bervariasi tergantung pada bahasa yang ditranskripsi.
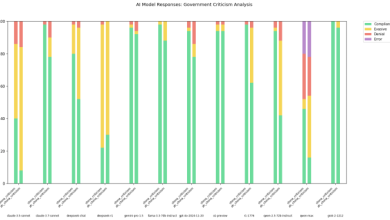
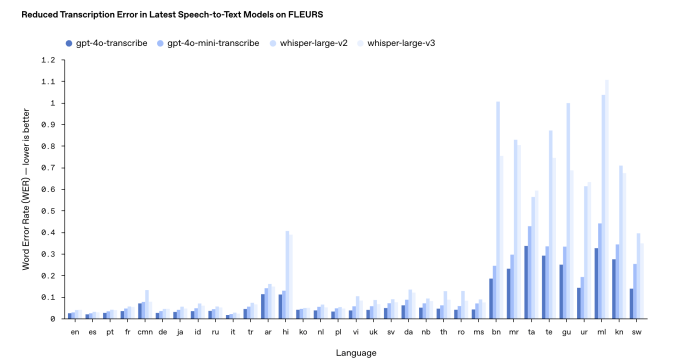
Menurut tolok ukur internal Openai, GPT-4-Transcribe, semakin akurat dari dua model transkripsi, memiliki “tingkat kesalahan kata” mendekati 30% (dari 120%) untuk bahasa indic dan Dravidian seperti Tamil, Telugu, Malayalam, dan Kannada. Itu berarti tiga dari setiap 10 kata dari model akan berbeda dari transkripsi manusia dalam bahasa -bahasa tersebut.
Dalam istirahat dari tradisi, Openai tidak berencana untuk membuat model transkripsi baru tersedia secara terbuka. Perusahaan secara historis yang dirilis versi baru bisikan untuk penggunaan komersial di bawah lisensi MIT.
Harris mengatakan bahwa GPT-4O-Transcribe dan GPT-4O-Mini-Transcribe “jauh lebih besar dari Whisper” dan dengan demikian bukan kandidat yang baik untuk rilis terbuka.
“[T]Hei bukan jenis model yang bisa Anda jalankan secara lokal di laptop Anda, seperti Whisper, “lanjutnya.”[W]E ingin memastikan bahwa jika kami merilis hal -hal di open source, kami melakukannya dengan cermat, dan kami memiliki model yang benar -benar diasah untuk kebutuhan spesifik itu. Dan kami pikir perangkat pengguna akhir adalah salah satu kasus paling menarik untuk model open-source. ”
Diperbarui 20 Maret 2025, 11:54 AM PT untuk mengklarifikasi bahasa di sekitar tingkat kesalahan kata dan memperbarui bagan hasil benchmark dengan versi yang lebih baru.