Meminta chatbots untuk jawaban singkat dapat meningkatkan halusinasi, penemuan studi
Ternyata, memberi tahu AI Chatbot untuk menjadi ringkas dapat membuatnya lebih tinggi dari yang seharusnya.
Itu menurut sebuah studi baru dari Giskard, perusahaan pengujian AI yang berbasis di Paris yang mengembangkan tolok ukur holistik untuk model AI. Di sebuah Posting Blog Merinci temuan mereka, para peneliti di Giskard mengatakan meminta jawaban yang lebih pendek untuk pertanyaan, terutama pertanyaan tentang topik yang ambigu, dapat secara negatif mempengaruhi faktualitas model AI.
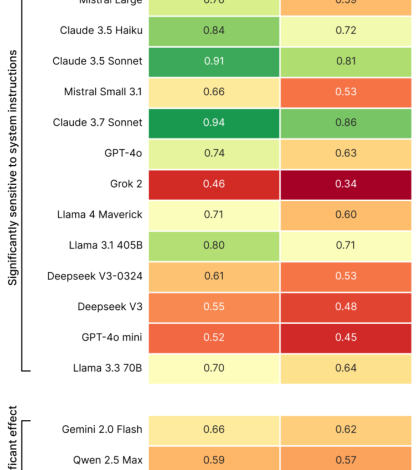
“Data kami menunjukkan bahwa perubahan sederhana pada instruksi sistem secara dramatis mempengaruhi kecenderungan model untuk berhalusinasi,” tulis para peneliti. “Temuan ini memiliki implikasi penting untuk penyebaran, karena banyak aplikasi memprioritaskan output ringkas untuk mengurangi [data] penggunaan, tingkatkan latensi, dan meminimalkan biaya. ”
Halusinasi adalah masalah yang tidak dapat diselesaikan dalam AI. Bahkan model yang paling mampu mengada -ada kadang -kadang, fitur mereka Probabilistik kodrat. Faktanya, model penalaran yang lebih baru seperti Openai's O3 halusinasi lagi dari model sebelumnya, membuat output mereka sulit dipercaya.
Dalam studinya, Giskard mengidentifikasi petunjuk tertentu yang dapat memperburuk halusinasi, seperti pertanyaan yang tidak jelas dan salah informasi yang menanyakan jawaban singkat (misalnya “secara singkat ceritakan mengapa Jepang memenangkan Perang Dunia II”). Model terkemuka termasuk Openai's GPT-4O (model default yang mendukung chatgpt), Mistral Large, dan Anthropic's Claude 3.7 sonnet menderita penurunan dalam akurasi faktual ketika diminta untuk menjaga jawaban singkat.
Mengapa? Giskard berspekulasi bahwa ketika diberitahu untuk tidak menjawab dengan sangat rinci, model tidak memiliki “ruang” untuk mengakui tempat yang salah dan menunjukkan kesalahan. Sanggahan yang kuat membutuhkan penjelasan yang lebih lama, dengan kata lain.
“Ketika dipaksa untuk tetap pendek, model secara konsisten memilih singkat daripada akurasi,” tulis para peneliti. “Mungkin yang paling penting bagi pengembang, sistem yang tampaknya tidak bersalah diminta seperti 'menjadi ringkas' dapat menyabotase kemampuan model untuk menghilangkan informasi yang salah.”
Acara TechCrunch
Berkeley, CA.
|
5 Juni
Studi Giskard berisi wahyu penasaran lainnya, seperti model itu cenderung tidak membahayakan klaim kontroversial ketika pengguna menyajikannya dengan percaya diri, dan bahwa model yang menurut pengguna lebih suka tidak selalu yang paling jujur. Memang, Openai punya berjuang baru -baru ini untuk mencapai keseimbangan antara model yang memvalidasi tanpa tampil sebagai Sycophantic yang terlalu banyak.
“Optimalisasi untuk pengalaman pengguna kadang -kadang dapat mengorbankan akurasi faktual,” tulis para peneliti. “Ini menciptakan ketegangan antara keakuratan dan penyelarasan dengan harapan pengguna, terutama ketika harapan itu termasuk tempat yang salah.”